Covid-19 has caused a lot of disruption (and not in a good way) to many companies and industries, ours included. One thing that it has done, whether in a detrimental or constructive way, is to force many of us to slow down in almost every aspects of our lives. While working from home does have its benefits, there is a difference between working from home with and without a bunch of yelling kids. While there may be those who can serenely drink their cappuccino while their kids are swinging like primates from the ceiling fan, many of us are juggling trying to get work done and trying to survive the gauntlet of emotions when it comes to educating your own kids, depending on their age. For me, this is the age where they think running around the garden stark naked screaming in the middle of the afternoon is their God given right.
But the flip side of it is that, once they are all slumbering away their misdeeds of the day, there is indeed that peace between 11 pm and 3 am that one can truly feel the serenity of a cloistered monk, and get things done. One of the things that I would suggest to do, is to probably do a backup of your data and laptop while you have time.
For me, one of the easiest and quickest way to do this is to just clone the entire drive you want to backup. In this short article, we will see how we can clone to a larger or equivalent drive (HDD or SSD) using this great software called Clonezilla.
Now, if you want to clone a larger drive to a SMALLER one, that might be a bit trickier, but it can possibly be done but that’s beyond this article. This is straight up backing up by cloning.
One of the frustrating thing is that there are so many software out there claiming to get this done. Minitool Partition Wizard used to be a good tool which I used previously, but the new version 12 now tricks you into doing all the steps for cloning and when you click ‘Start’, it pops up that this feature is only available in the Paid version. The previous versions (if you have) allows you to do it, but unfortunately I removed it earlier and I don’t have the offline installer for it, as all installers now automatically download the new version. Other software like Aomei Partition Assistant actually gets to the point where you can execute the cloning, but frustratingly tries to install Windows PE and fails, and then tries to go Pre-Os mode and just hangs there not knowing what to do.
Previously I did an extremely difficult cloning of a 1TB drive full of errors using DDRescue, a very, very good tool especially for drives that are strewn with bad sectors and errors which none of the bloatware out there can resolve and even Clonezilla had issues with. It took me a good part of one day just to get it done but it finally did and I managed to save all data from a drive that was dying. Again, DDRescue is a good tool, but for non-error, straight up clone, I think Clonezilla is the easiest and best.
First of all, for Clonezilla, the easiest way is to create a Live USB flash drive and use that. I used Rufus USB which is pretty straightforward but there are other ways to get it done as well. Go on to https://clonezilla.org/liveusb.php to get a full idea of how to do this.
Secondly, prepare the target drive where you want to dump your drive to. A HDD/SSD would likely need an enclosure to house it. For the SSD, make sure you know which type it is and get the enclosure from Lazada or Shopee. These are fairly cheap . I got mine for around RM25 – RM30 or somewhere there. Mine looked like this:
Plug the new drive into the enclosure.
Once done, just plug in the Clonezilla USB in and reboot and ensure you are booting from USB over your BIOS. This may or may not be tricky if you are booting with UEFI with secure boot, and you may need to disable it and use legacy boot to get the USB to boot for now.
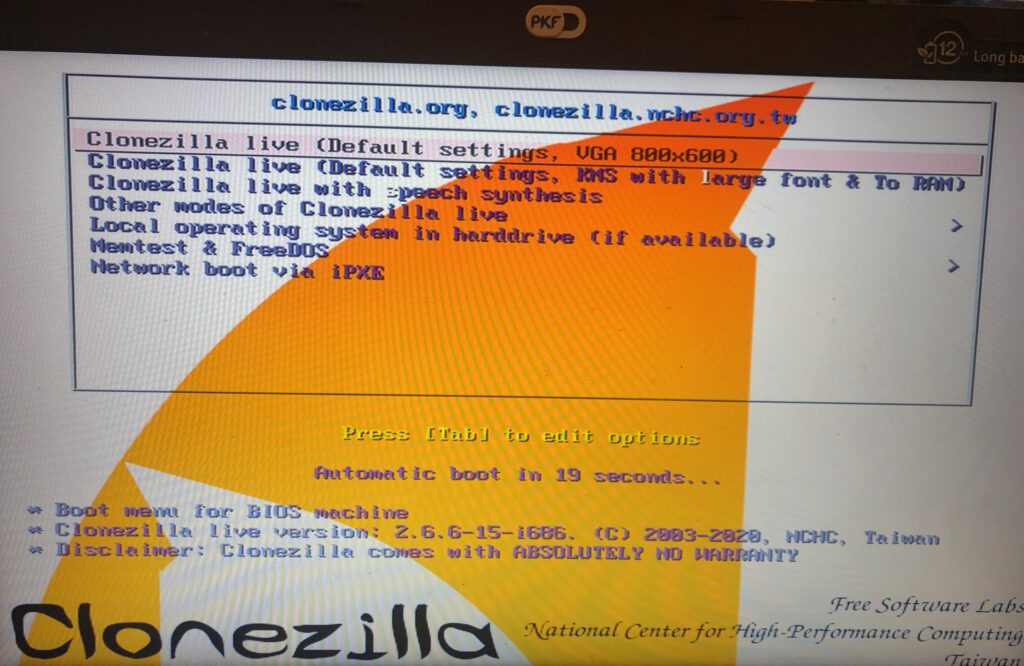
Once booted, you are welcomed to the tiny Clonezilla OS, which is Debian I believe.
Go ahead with the default settings, but now you can plug in your enclosure USB drive, which Clonezilla should be able to detect as it boots up. It takes less than a minute and we are now dump into the main screen. Select the keyboard settings as it is, and start Clonezilla.
Select device-device as this is what you are looking at. I would opt to select “Expert mode” as this provides you with more options as you are cloning to a larger storage. If you are doing a direct mirror to a similar sized storage, using beginner mode may be less work.
Select Disk to Local Disk and at this point Clonezilla should be able to see a few things: your current drive and the drive that is plugged in using the enclosure. As in all things, you need to be wary which is which and not copy it wrongly.
Select your current drive as source and the enclosure drive as the destination.
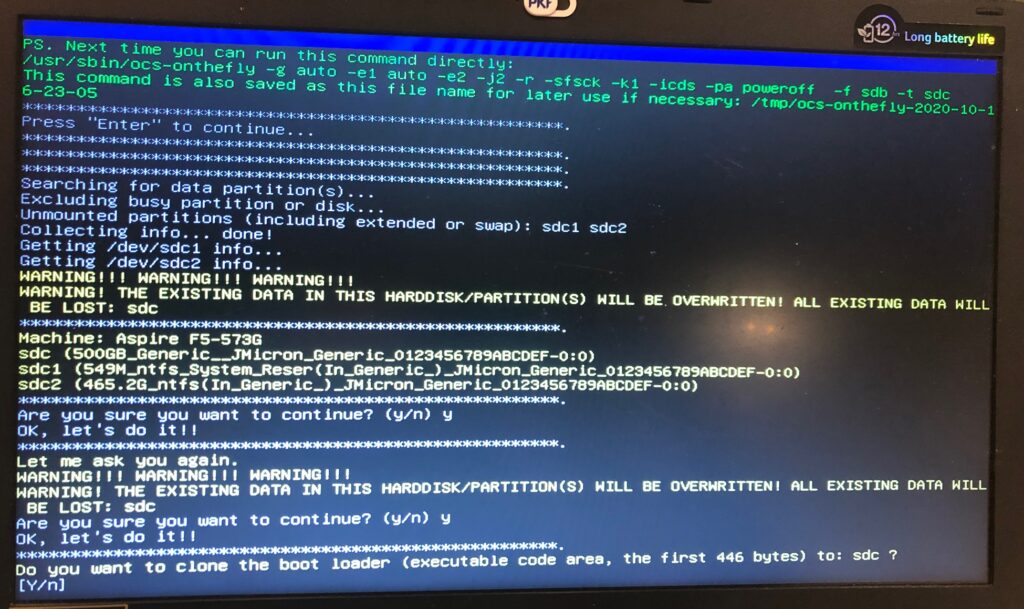
In the expert mode, you have quite a fair bit of options. Just make sure -r option is there as this resizes the filesystem automatically and in the other part of expert parameters to select -k1 which is to create partition table proportionally.
If you are sure that the drive is fine and you are just doing a backup, then skip the checks for errors of the source file system which would save some time. If you do have errors, my suggestion would be to go to DDRescue option as opposed to Clonezilla. I tried Clonezilla on a dying drive and it didn’t work too well.
Finally, select what you’d like to do once the whole thing is done, to reboot, shutdown etc.
We later have a whole bunch of funny excerpt to confirm if we actually know what we are doing. Because I was cloning the OS drive, I cloned the boot loader along with it.
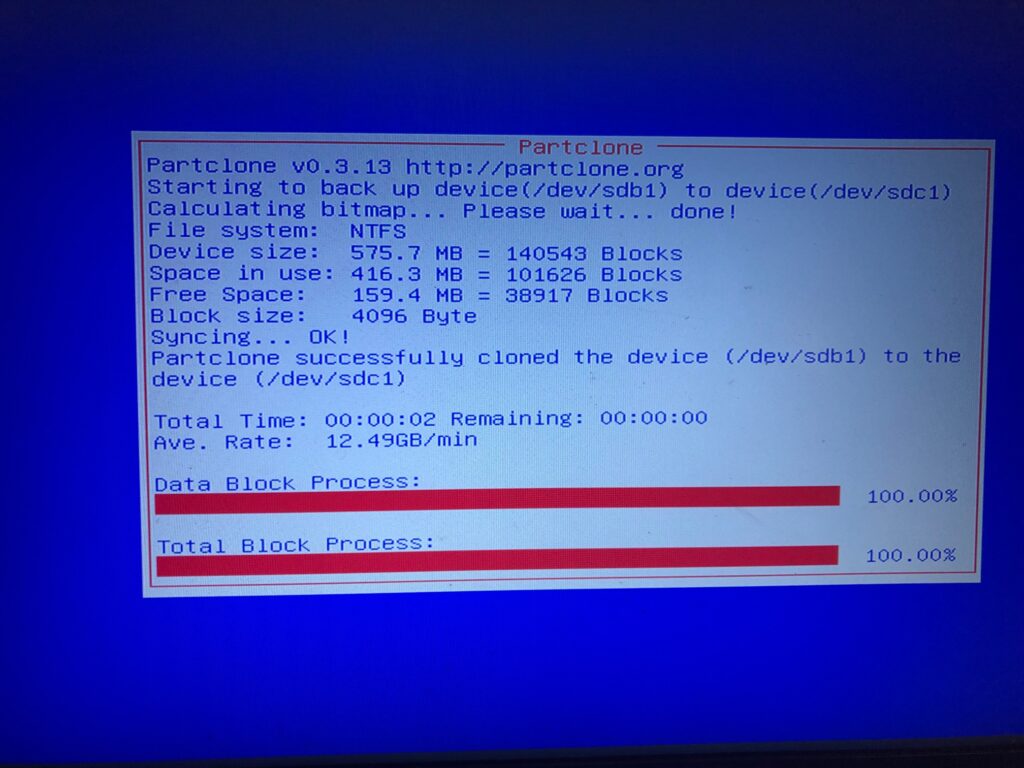
And finally we are off. It takes only a short while – I guess less than half an hour to get it done.I didn’t take time of it, I just let it run and did my own things and within an hour checked again and found it was completed. Based on the average rate and my 250GB, it’s roughly around 20 minutes or so.
Once that is completed, shut down your laptop, take out the old SSD and swap it with a new one and voila you now have a new expanded SSD on your OS drive. You can do frequent backups to your laptop as well by doing the same method – but getting a same size SSD – and it would save you years of trouble (if you don’t change your laptop). Even if you upgrade your laptop, you can still use the backup as an external USB drive and copy the data there on your own time.
If you plugin the enclosure that had your previous OS image, you may get the problem of Windows making it offline due to signature collisions. Just right-click and select Online for the drive and you should be good to go.
Well, that’s it.
The reason for this article is that it’s frustrating working through software like Aomei Partition or Minitool (latest version) Partition Wizard etc because there are so many things that cannot work – e.g installing Windows PE, going into Pre-Os mode and in Aomei Partition, just hanging my laptop and not moving forward. The preference is just to get a simple solution that works without forcing us to buy professional versions etc or wasting our time with software gymnastics that we don’t need. Clonezilla (or the even better DDRescue) would be the go-to software for this.
Now, stay safe, and get your kids down from the ceiling fan!
Today at 10/10 is World Mental Health Day, and we would like to just take a short break from technical articles for this short article on Mental health.
I’ll start it with one incident that I experienced when I was just starting out work at a Multinational company more than 20 years ago. I was young, just graduated from university, looking forward to contributing into the workforce. Heck, I would have paid employers to give me a chance to work. My first day at work, since I was paid RM1,000 and technically wasn’t even an employee but a contract person, I didn’t have any laptop, devices or anything assigned to me. I would carry an old empty laptop bag belonging to my dad, filled with blank papers so that I could look important to work. I was very proud to be getting on the train the first day at work, with a tie and shirt and a bag filled with blank papers.
On my first week at work, I messed up at something (till today, I blame my immediate so called ‘mentor’ who basically threw me under the bus for that incident), and my boss was so pissed off at me, he literally threw the Solaris manual at me (those who has seen the old Sun Microsystem would know) and screamed for me to read the f***ing book and get out of his room and fix the mess. He warned me if I messed up again, I don’t need to step into the office ever again.
At that time, I just thought, Man, I will definitely not mess up again and went on with life and eventually, grew into the role and stayed in the company for the next 5 years. I really thought, at that point of time, that it was absolutely normal to be treated like that, or to have my career being threatened every day to keep me on my toes – because I thought, well, that’s worklife. That’s how it is. This is the rite of passage.
The reason for this anecdote is that, many times, our view of the world is derived from our direct experience with it. Just because we went through that sort of experience, came out stronger and took it in the chin, we think thats the norm and proceed to do the same for the next generation under us.
Until we come to realise, that people are built differently. And being built differently is absolutely fine.
At PKF Avant Edge, we are trying to create more awareness on the need to understand mental health. See, back in the days, there is always a taboo regarding ‘mental health’. Even when younger, in school, when we see someone acting strange, we just categorise it as being ‘mental’, or worse. In fact in Malaysia, people seemed to associate Tanjung Rambutan (that has a hospital treating mental illness) as where people would go if they acted ‘crazy’. These are notions that we, as a society, must move forward from. While we do not purport to be a company that champions mental awareness publicly, we still must take effort to understand the correlation between mental health and work productivity.
Work stress is unavoidable, especially during these trying times in Covid-19. While some may undertake work stress and manage it properly, some may find it harder. Mental health is just as important as physical health but the problem sometimes is that mental health isn’t manifested in a way that is obvious. You can’t take a thermometer and point it at someone and confirm they have challenges in mental health the way you do for physical. In fact even observation isn’t clear – when someone has a stomachache, it’s fairly obvious in his/her facial expression or general disposition. Many people may associate poor mental health with poor social skills, moodiness, anger, being anti-social and all the negative attributes we consider not the social norm. While these may be true, it isn’t accurate – because gregarious people, people who laugh and joke around and are extroverted externally – they may also be having poor mental health without us knowing it. To make matters worse, employers are often suspicious that employees may be using this mental health card to explain away certain things at work that they (the employer) may deem as poor performance due to the fact that the employees are lazy, or not up to par, instead of calling it mental health.
So it goes both ways. On one hand, employees to look at the view point of the employer – that they are paying salary to someone to function at the bare minimum of what they are being paid to do, and if this cannot be achieved, then the employer do have the right to question and to see how improvement can be done to do what they can to make the person fit the job or the job fit the person – otherwise, it may be better to part ways mutually. On the other side, employers need to understand that there should not be any discrimination, that they must make the best effort to provide an environment that caters to mental wellness and not just a non-stop cycle of pressure and deadlines.
PKF AE has some ways to go before we reach a point that we can be comfortable with the balance of both views. Instead of viewing both as opposing each other (promoting productivy and promoting mental health), we must view it as complimenting each other, and put in policies that allows us to be both productive and be well mentally.
Some of the things we provide include conversing openly about this topic and to ensure that it is not something to be ashamed of, but to be aware about. We can provide support by allowing employees to be taken off some projects that may be considered far too stressful (removing from the front lines, so to say), lowering their workload temporarily, reassigning them to other work (e.g backoffice, or for those stressed with administration, then more customer facing etc). At the end, it depends on what are the triggers/contributing factors to their mental wellness. We allow our employees to schedule with their doctors, work on more flexible timing and locations.
In some cases even, if they need complete unpaid furlough or isolation for a few months, depending on the situation, we can provide even the option to be re-integrated back to the company after their furlough, while providing informally any assistance we can afford to provide.
What we lack currently are actual policies and procedures to address mental wellness, which we are working on as a company. There are still so many questions on how to handle this, while ensuring the productivity of our company is also looked after. It is a balance, that while we have not achieved yet completely, we have at least started on, with the awareness and support for World Mental Health Day 2020.
A break from our compliance articles, here is a simple hack for a problem plaguing us for some time. Our backup program is fairly comprehensive…we use a lot of different backup options. We are of the philosophy that you can never back up enough. Never. And anyway, PKF Malaysia is pretty big. We have offices in KL, Penang, Ipoh, KK, Sandakan, KB, Cambodia under us. That’s a lot of data. One of the backup options we use is automated to large external USB drives for archival.
While not the primary means of backup, it’s still pretty frustrating when we faced a strange issue with two of our external drives acting up all of a sudden. We don’t know why. They were working well enough, but suddenly, just stopped functioning well. Like a teenage kid. What happened was, we found that backups would regularly hang to the external drives (we have 2 of the same brand). At first, we thought it was just a connection issue (USB failing etc) and we took them out and tried it on various Windows servers (not *nix as we didn’t want to mess around with those, as they were critical). The idea anyway was to have these function on Windows only. Same issue was observed on all Windows servers and even on workstations and laptops.
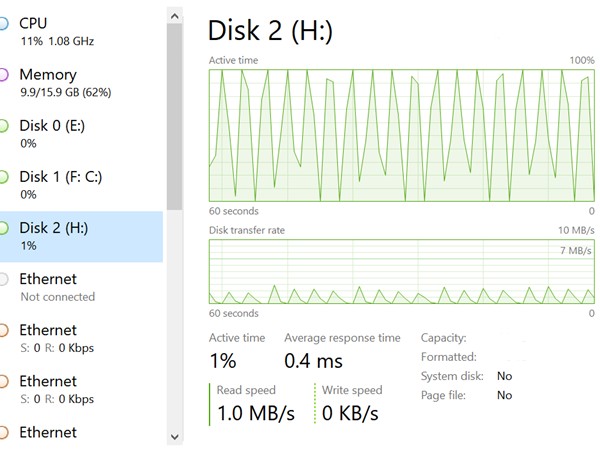
The issue was simply excruciatingly slow transfer speeds and a graph looking similar to this:
Now that doesn’t look like a healthy drive.
What is happening here was that it would start whirring up once we tried to transfer files and the active time of the disk would be 1%. In a second, it would hit 50% and then within 2-3 seconds hit 100%. At that moment, the transfer speed had probably crawled up to around 15-20 MB/s and it would drop again to zero as the disk starts to recover. And it would happen again and again. This made data transfers impossible, especially big backups we did.
Troubleshooting it, after we tried updating firmware to no success:
a) Switched cables for the drives: Same issue
b) Switched servers / workstations : Same issue. We note we didn’t try it on *nix because those were critical to us but as an afterthought, it was probably something we could have done to isolate if the problem was the drive or the OS.
c) Switched other external drives: Works fine. So we kept one of these older drives as a control group so we know what is working
d) Switched USB3.0 to USB2.0: This is where we began to see something. The USB2.0 switch made the drives work again. However, transferring at USB2.0 speeds wasn’t why we purchased these drives anyway, but again, this is a control group, which is very important in troubleshooting as it provides a horizon reference and pinpoint to us where the issue is.
We ran all the disk checks on it and it turns out great. Its a healthy drive. So what is the issue?
We opened a support ticket to the vendor of this drive and surprisingly got a response within 24 hours asking us the issue asking us for the normal things like serial number, OS, error screens , disk management readings etc. So we gave and explained everything and then followed up with:
We have already run chkdsk, scannow, defrag etc and everything seems fine. Crystaldisk also gave us normal readings (good) so we don’t think there is anything wrong with the actual drive itself. We suspect it’s the UASP controller – as we have an older drive running USB (Serial ATA) which was supposed to be replaced by your disk – and it runs fine with fast transfer speed. We suspect maybe there is to do with the UASP connection. Also we have no issues with the active time when running on the slower 2.0 USB. Is there a way to throttle the speed?
We did suspect it was the UASP (USB Attached SCSI Protocol) that this drive was using. Our older drives were using traditional BOT (Bulk Only Transport) and the USB3.0 was working fine. Apparently UASP was developed to take advantage of the speed increases of USB3.0. I am not a storage guy, but I would think UASP is able to handle transfers in parallel while BOT handles in sequential. I would think UASP is like my wife in conversation, taking care of the kids, cooking, looking at the news, answering an email to her colleague, sending a whatsapp text to her mum and solving world hunger. All at once. While BOT is me, watching TV, unable to do anything else until the football game is over. That’s about right. So it’s supposed to be a lot faster.
How UASP works though is it requires both the OS and the drive to support it. The USB controller supporting this in Windows is the uaspstor.sys. You can check this when you look at the advanced properties in device manager and clicking on the connected drive or through disk management screen and view the detailed properties. Interestingly, our older drives loaded usbstor.sys which is the traditional BOT.
UASP is backward compatible to USB2.0, so we don’t really know why USB2.0 worked while USB3.0 didn’t. The symptoms were curiously the same. Even at USB2.0, the active time would ramp up, but we think, because USB2.0 didn’t have enough pipe to transfer, the transfer rates were around 30 MB/s and the active time of the drive peaked around 95%. So because it never hit the 100% threshold for the drives to dial down, we don’t see the spike up and down like we see in USB3.0. However, active time of 90+% still isn’t that healthy, from a storage non-expert perspective.
The frustrating thing was, the support came back with
Thank you very much for the feedback. Regarding to the HDD transferring issue, we have to let you know that the performance of USB 3.0 will be worse when there is a large amount of data and fragmented transmission. The main reason is the situation caused by the transmission technology not our drive. For our consumer product, if the testing result shown normal by crystaldiskinfo, we would judge that there is no functional issue. Furthermore, we also need to inform you that there is no UASP function design for our consumer product. If there are any further question, please feel free to contact us.
One of the key things I always tell my team is that tech support, as the first line of defence to your company MUST always know how to handle a support request. The above is an example how NOT to be a tech support.
Firstly, deflecting the issue from your product. Yes, it may be so that your product is not the issue. But when a customer comes to you asking for help, the last thing they want to hear is, “Not my problem, fix it yourself.” That’s predominantly how I see tech support, having worked there for many years ourselves. We have a secret script where we need to segue the complaint to where we are no longer accountable. For instance – did you patch to latest level? Did you change something to break the warranty? Did you do something we told you not to do in one of the lines amongst the trillion lines in our user license agreement? HA!
So no, don’t blame the transmission technology. Deflecting the issue, and saying the product is blameless is what we in tech support call the “I’ll-do-you-a-favor” manoeuvre. Because here, they establish that since they are not obligated to assist anymore, any further discussion on this topic is a ‘favor’ they are doing for you and they can literally exit at any point of time. It makes tech support look good when the issue is resolved and if the going gets too tough, it’s not too hard to say goodbye.
Secondly, don’t think all your clients are idiots. With the advent of the internet, the effectiveness of bullshitting has decreased dramatically from the times of charlatans and hustlers peddling urine as a form of teeth whitening product. They really did. Look it up. Maybe, a full drive would have some small impact to the performance. But a quick look at the graph shows a drive that is absolutely useless, not due to a minuscule performance issue but to an obvious bigger problem. I mean how is it that we can make a logic that once it reaches a certain percentage of drive storage it is rendered useless?
Lastly, know your product. Saying there is no UASP function is like us telling our clients PCI-DSS isn’t about credit cards but about, um, the mating rituals of tapirs. The tech support unfortunately did not bother to get facts correct, and the whole response came across as condescending, defensive and uninformed.
So now, we responded back:
I am not sure if this is correct, as we have another brand external drive working perfectly fine with USB3.0 transmission rates, whether its running a file or transferring a file to and from the external drive. Your drive performance is problematic when a file was run directly from the drive, and also transmission to copy file TO the drive. As we say, the disk itself seems ok but regardless, the disk is not usable when connecting to our USB 3.0 port, which most of our systems have, that means the your external drive can only work ok for USB 2.0. We suggest you to focus the troubleshooting on the UASP controller.
Further on, after a few back and forth where they told us they will recheck we responded
Additional observation: Why we don't think its a transmission problem, aside from the fact other drives have no issues, is that when we run a short orientation video file from your drive, your drive active time ramps up to 100% quickly - it goes from 1% - 50% - 100%, then the light stops blinking, and it drops back to 1% again, and it ramps up again. This happens over and over. We switched to other laptops and observed the same issue. On desktops as well, different Windows systems. What we don't want to do is to reformat the whole thing and observe, because, really, the whole reason for this drive is for us to store large files in it as a backup, and not have a backup of backup. We have also switched settings to enable caching (and also to disable it) - same results. The drives are in NTFS and the USB drivers have been updated accordingly. We have check the disk, ran crystaldisk, WMIC, defrag (not really needed as these are fairly new), but all with same results. We dont find any similar issues online, of consistent active time spikes like we have shown you, so hopefully support can assist us as well.
After that, they still came back saying they needed more time with their engineers and kept asking us whether other activities were going on with the server and observing the disk was almost full. We did a full 6 page report for them, comparing crystaldiskinfo results of all our other drives (WD, Seagate) and point out specifically their disks were the ones having the spike issues and requested them again to check the controllers.
After days of delay, stating their engineers were looking into it, and our backups were stalled they came back with:
Regarding to the HDD speed performance, we kindly inform you that the speed (read/write) of products will be limited by different testing devices, software, components and testing platforms. The speed (read/write) of products is only for reference. From the print screen that you provide, we have to let you know that the write speed performance is slow because there are data stored in this drive. Kindly to be noted that the speed may vary when transferring huge data as storage drive or processing heavy working load as storage drive. Besides, please refer to the photo that we circled in red, both different drive have different data percentage. For our drive, the capacity is near full, then it is normal to see the write speed performance slower than other drive.
This response was baffling . It wasn’t just slow. It was unusable because there is data stored in this drive? Normal to see write speed slower?
After almost a week and half talking to this tech support, they surmise (with their engineers) that their drives cannot perform because there is data stored in it. It makes one wonder then why are disk drives created if not to store data.
Our final response was:
We respectfully disagree with you. Your drive is unusable with those crystaldisk numbers and I am sure everyonewill agree to that. You are stating your drive is useless once it starts storing data, which is strange since your product is created to store data. Whether the drive is half full or completely full is not the point, we have run other drives which are 95% full and which are almost 100% full with no issues. Its your drive active time spiking up to 100% for unknown reasons, and we have not just one but two of your drives doing this. We have insisted you to look at the controller but it seems you have not been able to troubleshoot that. I believe you have gone the limit in your technical ability and you are simply unable to give anymore meaningful and useful support, and I don't think there's anything else you can do at that will be of use for us .We will have to mark it out as a product that we cannot purchase and revert back to other drives for future hard drive purchase and take note of your defective product to our partners.
And that was the end. Their tech support simply refused to assist and kept blaming a non-existent event (data are stored in the disk), which had absolutely zero logical sense. It was a BIZARRE tech conclusion that they came to and an absolute lesson of what not to do for tech support.
That being said, we temporary resolved the issue with a workaround by disabling one of our servers using UASP and force it to use BOT. This hack was taken from this link, so we don’t get the credit for this workaround.
Basically you go to C:\Windows\System32\drivers and just rename uaspstor.sys to uaspstor.sys.bk or whatever to back it up. Then copy usbstor.sys to uaspstor.sys.
Depending on your system, you might have to do this in safe mode. We managed to do it without. Reboot and plugged in the troublesome drive and now it works. Some other forums says to go to the registry and basically redirect the UASPStor Imagepath to usbstor.sys instead of uaspstor.sys. However, this is problematic as when you try to plugin a traditional external drive using BOT, it doesn’t get recognised, because we think that the usbstor.sys is locked for usage somehow. So having a usbstor.sys copied to uaspstor.sys seems to trick Windows into using the BOT drivers instead while thinking it’s using this troublesome UASP driver.
Now obviously this isn’t a solution, but it’s a workaround. For us, we just plug these drives into one of the older servers and used it as a temporary backup server until we figure out this thing in the long run.
But yeah, the lesson was really in our interaction with tech support and hopefully we all get better because of this! For technical solutions and support, please drop us a email or the comment below and we will get to you quickly and in parallel (not sequentially)!
One of the things that advisors and consultants do, as part of our journey to get our clients to comply to PCI-DSS is the inevitable (and unenviable) task of dealing with vendors. A vendor can be classified as anyone or any company that is selling a service or a product to our client, that directly or indirectly relates or affect their PCI-DSS compliance. Examples include firewall vendors, encryption technology vendors, HSM vendors, server vendors, Virtual solution vendors, SIEM vendors, SOC providers, call center solution vendors, telemarketing services, hosting providers, cloud providers and the list goes on. Having dealt with hundreds of vendors over the course of the decade we have come across all kinds: some are understanding, some are hostile, some are dismissive, some are helpful and the list goes on.
But there is always a common denominator in vendors: They all start by justifying why their product or service is:
a) Not relevant to PCI-DSS compliance (because they don’t store card data, usually)
b) Why their product is PCI acceptable (but it’s really not, or when we have questions on certain aspects of it)
It always begins with these two start points and it can then branch off into a myriad of different plots, twists, turns and endings, very much like a prolonged Korean drama.
With this in mind, we recently had an interesting call with one of such vendor, who basically runs a fairly important PCI subsystem for one of our clients. The problem was that their logs and console had two things that we sometimes find: the combination of truncated and hashed values of a credit card information, grouped together.
Now, just a very quick recap:
a) Truncated card data – This is where you see parts of the card replaced by XXXX characters (or any character) where the full card number is not STORED. Now it must be noted that TRUNCATED and MASKED are treated differently, although oftentimes confused and used interchangeably. When we say something is MASKED, it generally means the PAN (Primary account number) is stored in full but not displayed in full on the console/application etc. This applies sometimes to call centers or outsourced services where full PAN is not required for back office operations but for reconciliation or references. TRUNCATED here means even in storage, the full PAN is not present.
b) Hashed Card Data – Hashing means its a one-way transformation of card data into a hash value with no way to reverse it (Unlike encryption). If we use a SHA-256 hash algorithm on a PAN, you get a fixed result. Fraud management systems may store this hash PAN in order to identify transactions by that particular card (after hashing), and not worry about the actual card data being stored. It’s like hashing of passwords where the actual password isn’t known.
It’s to be noted, when done properly, these two instances of data may even be considered entirely out of scope of PCI-DSS. The problem here is when you have both of these stored together and correlated together, it renders the data protection weaker than just having one control available. This is probably where the concept usually gets lost on clients implementing these controls, as we have seen many times before – for example, tokenized information being stored together with truncated values.
Even PCI-DSS itself states clearly in the standard item 3.4 in the Note, that “Where hashed and truncated versions of the same PAN are present in an entity’s environment, additional controls must be in place to ensure that the hashed and truncated versions cannot be correlated to reconstruct the original PAN.”
To clarify, it doesn’t mean that it CANNOT be done, but additional controls must be in place. A further look at this is found in the Tokenization Product Security Guidelines Supplementary document:
IT 1A-3.b: Verify that the coexistence of a truncated PAN and a token does not provide a statistical advantage greater than the probably of correctly guessing the PAN based on the truncated value alone.
Further on:
…then the vendor provides documentation to validate the security strength (see Annex C – Minimum Key Sizes and Equivalent Key Strengths for Cryptographic Primitives) for each respective mechanism. The vendor should provide a truncated PAN and irreversible token sample for each.
And furthermore in Tokenization_Guidelines_Info_Supplement.pdf:
Note: If a token is generated as a result of using a hash function, then it is relatively trivial effort for a malicious individual to reconstruct original PAN data if they have access to both the truncated and hashed version of the PAN. Where hashed and truncated versions of the same PAN are present in the environment, additional controls should be in place to ensure that the hashed and truncated versions cannot be correlated to reconstruct the original PAN.
So in short, at anytime we see there are hashed values and truncated value together, we need to validated further on the controls. A good writeup is found here at another blog which summarises the issues surrounding this.
However, as our call with this particular vendor continued on, he demonstrated just how vendors should or should NOT approach PCI-DSS compliance, which sort of inspired this post:
A) DON’T place yourself as the topical expert in PCI-DSS: Don’t. Not because you are not, but because you are representing a product or a service, so you always view certain things through a lense you have been trained on. I know, because I was with vendors for many years and most of our consultants are from vendor backgrounds. He immediately started by stating, he is extremely well verse with section 3.4 of PCI-DSS (which basically talks about the 4 options of protecting card holder data stored), and that he has gone through this conversation many times with consultants. This immediately sends the QSA red flags, once the vendor starts moving away from what they know (their product) to what they may think they know but generally may not (PCI-DSS), and in general we don’t want to put the auditor on defence once vendors sound defensive. It should be collaborative. DO state clearly that we are subject matter experts in our own field and we are open to discussions.
B) DON’T recover by going ‘technical’: In his eagerness to demonstrate his opinion on PCI, he insisted that we all should know what 3.4 is about. Concerning the four controls stated in PCI-DSS (token, truncation, hashing, encryption), he claimed that their product is superior to what we are used to because his product has implemented 3 out of 4 of these controls (hashing, truncation and encryption) and he claims this makes it even more compliant to PCI-DSS. At this point, someone is going to call you out, which is what we did reluctantly as we were all staring at each other quizzically. We had to emphasize we really can’t bring this to the auditor or justify this to our client who was also on the call, as this is an absolute misinterpretation of PCI-DSS, no matter what angle you spin. PCI never told us to implement as many of these options as possible. In fact, clearly stating if more than one of these are introduced, extra care must be taken in terms of controls that these cannot be correlated back to the PAN. We told him this was a clear misinterpretation to which his response was going into a long discourse of where we consultants were always ‘harping’ on impractical suggestions of security and where we always think it’s easy to crack hashes just because we know a little bit about ‘rainbow tables’. We call this “going technical”. As Herman Melville, the dude that wrote Moby Dick puts it:
“A man of true Science uses but few hard words and those only when none others will serve his purpose; whereas the smatterer in Science… thinks that by mouthing hard words he understands hard things”. – Dude that wrote Moby Dick.
Our job is really to uncomplicate things and not to make it sound MORE complicated, because there may always be someone in the room (or video conference) who knows a little more than what they let on.
DO avoid jargonizing the entire conversation as it is very awkward for everyone, especially for those who really know the subject. DO allow input from others and see from the point of view of the standard, whether you agree or disagree or not and keep in mind the goal is common: to make our client compliant.
C) DO find a solution together. As a vendor, we must remember, the team is with the client. The consultant is (usually) with the client. So its the same team. A good consultant will always want vendors to work together. We always try to work out an understanding if vendors cannot implement certain things, then let’s see what we can work on, and we can then talk to the the QSA and reason things out. Compensating controls etc. So the solution needs to be together, and finally, after all those awkward moments of mansplaining everything to us, we just went: “OK, let’s move on, these are the limitations, let’s see where the solution is.” And after around 5 minutes or so, we had a workaround sorted out. Done. No need to fuss. So next step is to get this workaround passed by the auditor for this round and if not, then we are back again to discuss, if yes, then done, everyone is moving out to other issues. Time is of essence, and the last thing we need is each of us trying to show the size of our brains to each other.
D) Don’t namedrop and look for shorter ways to resolve issues. One of the weirdest thing that was said in the conversation after all our solution discussion was when the vendor said that he knew who the QSA was and he dropped a few names and said, just tell the QSA it’s so and so, and we’ve worked together and he will understand. Firstly, it doesn’t work like that. Namedropping doesn’t allow you to pass PCI. Secondly, no matter how long you have worked with someone, remember, another guy in the room may know that someone longer than you. We’ve been working with the QSA since the day they were not even in the country and for a decade, so we know everyone there. If namedropping was going to pass PCI, we would be passing PCI to every Tom, Dick, Harry and Sally around the world. No, it doesn’t work that way, we need to resolve the issues.
So there you have it. This may sound like a rant, but the end of the conversation was actually somewhat amicable. Firstly, I was genuinely appreciative of the time he gave us. Some vendors don’t even get to the table to talk and the fact that he did, I really think its a good step forward and made our jobs easier. Secondly, we did find the workaround together and that he was willing to even agree to a workaround, that’s a hard battle won. Countless vendors have stood their ground and stubbornly refused to budge even when PCI non-compliance was screaming at their faces. Thirdly, I think, after all the “wayang“, I believe he actually truly believed in helping our client and really thought that his product was actually compliant in all aspects. Of course, his delivery was awkward, but the intention was never to make life difficult for everyone, but to be of assistance.
At the end, the experience was a positive one, given how many discussions with vendors go south. We knew more of their solution, we worked out a solution together and more importantly, we think this will pass PCI for our client. So everyone wins. In this case, the Korean Drama ended well!
For more information on PCI-DSS, drop us a line at pcidss@pkfmalaysia.com and we will get back to you immediately! Stay safe!
It has been a while since our last post but as we are getting back up to speed to restart our work, our email engines are churning again with a lot of queries and questions from clients and the public on PCI-DSS, ISMS, ITSM, GDPR matters. We even have an odd question or two popping up regarding COVID-19 and how to secure against that virus. I don’t know. It’s a multi-billion dollar question which nobody can answer.
So while all these things are going, the one relentless constant we are still facing is: PCI-DSS deadlines. Despite the worldwide pandemic, we still get clients telling us they need to get their certificate renewed, their ASV scans done, their penetration testing sorted within x number of days. The reality of course is a bit more difficult. For example, once you have tested or scan, how does one remediate the issue when we cannot even get onsite to do proper testing? What about the development team, or the patching process, or the testing procedures and change management that needs to be done? The reality is simply, due to the pandemic, DELAYS will occur.
One of the main concerns are ASV scans, because ASV scans need to be done quarterly, there may be actual issues in remediation delays that may cause the company to miss the quarter.
How do we overcome this?
The main step is to always check with your QSA on this. I cannot repeat this ENOUGH. An organisation undergoing PCI-DSS, no matter what your size, especially if you are undergoing QSA certified program (Level 1 or Level 2 SAQ signoff from QSA) – ENGAGE your QSA to assist you. The QSA isn’t just supposed to come in at the end of your certification cycle, start poking holes into all your problems and tell you – you can’t pass because you missed our your internal VA back in Quarter 1. Or state your segmentation testing is insufficient at the end of your certification cycle. Or tell you that your hardening procedures are inadequate, with 1 month left to your certification cycle. The QSA needs to be in engagement at all times – or at the very least on a quarterly basis. Get them to do a healthcheck for you – all QSAs worth their salt should be able to do this. The mistake here is to treat your QSA as just an auditor and not onboard them throughout your certification cycle. An example is in the supplementary document from the council “Penetration-Testing-Guidance-v1_1” shows the possible involvement of the QSA:
In order to effectively validate the segmentation methodologies, it is expected that the penetration tester has worked with the organization (or the organization’s QSA) to clearly understand all methodologies in use in order to provide complete coverage when testing.
Pg 10 PCI Data Security Standard (PCI DSS) v1.1
It’s essentially critical to understand the relationship the QSA must have and the involvement they have, especially in the scoping part of PCI-DSS. The problem we often see is there is a disconnect between the company and their QSAs in terms of scope, or expectation, or evidences, which generally leads to A. LOT. OF. PAIN.
For ASV scans, a QSA may also provide ASV services provided these are properly controlled that there is proper segregation of duties and independence within the QSA/ASV company itself.
However, we have also done many companies whereby we provide the ASV scan and another QSA does the audit. Or the other way where we provide the QSA audit, and ASV is done by another company.
There is one example whereby we were auditing a company, and the ASV scans were done by another firm. We have been engaged from the start on a quarter basis and we highlighted to them that their Q1 ASV scan isn’t clean. We got on a call with the ASV company and worked together to ensure that the next quarter, these non compliant items would be remediated. So even with Q1 ASV not passed, at the end as QSA we still accepted the PCI recertification. PCI Council addressed this in FAQ 1152 – “Can an entity be PCI DSS compliant if they have performed quarterly scans, but do not have four “passing” scans?”
Without early engagement of the QSA and ASV, there would be a lot of problems once the recert audit comes around. In this case we could set the proper expectation early in the cycle for the customer to address.
Another possible instance is whereby the ASV themselves can pass a quarter scan with non compliant findings with compensating controls. This procedure is detailed out in section 7.8 of the ASV program guide, whereby within the quarter scan itself, before the expiry of that quarter, compensating controls are provided and validated and the ASV is able to issue an acceptable report for that quarter. This is important, because QSAs like to see 4 quarterly clean reports, and they throw a tantrum if they don”t get what they want. So in short, for ASV scans, do the following in this order:
a) Remediate all and get a clean report for the quarter; or
b) If you have non compliant for the quarter, engage your ASV, provide acceptable compensating controls, and attempt (not influence) with the ASV to accept/validate these controls and provide a clean report for the quarter but documented under Appendix B of the scan report summary; or
c) If for whatever reason, a clean report cannot be provided for the quarter, work closely with the ASV and the QSA to ensure that at least the next quarter or quarter after next remediation is correctly done. This is tricky because once the quarter report is out, it’s out of the ASV’s hands and into the QSA – on whether they can accept these reports or not. You can hang on to FAQ 1152 – but remember, FAQs are NOT the standard, so you are essentially in the hands of the QSA.
Those are your options for ASV, if there are any delays. DO NOT, in ANY CIRCUMSTANCE, MISS Your quarterly scan. Missing your scan is NOT THE SAME as getting a non compliant report. Missing your scan means there is no recourse but to delay your certification until you can get your 4 quarters in.
Finally before we sign off – let’s clarify here what a ‘quarter’ means. Some clients consider ‘quarterly’ scans to be their actual calendar year quarter. No. It’s not. Essentially a quarter is 3 months of a cycle of 12 months compliance year. A compliance year is not your calendar year (it could be, but it doesn’t have to be). So let’s divide this into two scenarios:
a) Where the ASV scans are required for the compliance year
In the case – the compliance year first needs to be defined, and this is usually done by identifying the signoff date of your AoC. For example if the QSA signed off your certification on April 1st, then that is where your quarter 1 begins. April – June; July – September; October – December; January – March. 4 quarters. You need to perform your ASV scan within the quarter, resolve the issues, and get the clean report out. This is CRITICAL to understand. Because many organisation fail this portion where they do not even perform any scans for the first few quarters and only pick up their PCI-DSS again mid way through and everyone is like: “Oops.” So while drinks and celebration are in the works once you signoff the AoC – your quarter 1 has also begun, so don’t drink too much yet.
So know your quarters. Start your scan early in the quarter, rescans must be done after remediation, and in case you need compensating controls, you need to get ALL THESE DONE within the quarter. If you perform your rescans in the next quarter, you are doomed. You MAY perform the rescan in this quarter and the clean report comes out next quarter for the current quarter – but all scans must be done within the quarter itself.
a) Where we have NO clue when the quarters are
As funny as this may sound (in a tragic way), there are many instances where we (wearing the ASV hat) gets plopped into situations where the client HAS NO CLUE when their compliance quarters are. I don’t know why this occurs. When I request them to check their AoC, or their QSAs for guidance, some can’t provide it. This is as great a mystery as the Sphinx itself. We call these internally, ‘Orphaned ASV scans’. These are projects where we are given the IPs and just told to shut up and scan the IPs. In this case because we onboard all ASV scans with quarters to define when we need to remind our customers, or escalate issues if the quarter runs out – we generally just use the date of the scan as a reference for quarters. So for instance, we provide a clean scan on April 31st. Since they are orphaned scans, without a compliance year/cycle for reference, we use the date of the scan report itself – meaning this scan expires 31st July.
By and large, we are seeing less and less of these orphaned ASV scans issues. Because QSAs these days are more engaged with customers and their customer service has also improved, it’s rare we find a client who isn’t aware of these cyclical requirements. Most clients, not just the large ones, are serviced by QSAs who themselves are reinventing themselves not just as auditors coming in once a year to observe and audit, but provide separate, independent units/consultants to assist healthchecks and support as well to enquiries pertaining to clients.
And a final note on this article – when we refer to ‘QSA’ or ‘ASV’ – we mean ControlCase International (QSA and ASV), whom PKF have been working with for close to a decade. We are not their representatives nor partners, but as our vendor, we’re keenly aware of how they do their certification and we try to manage our projects according to their expectations. As to why we do not want to become QSAs ourselves, we take independence and segregation of audit and operations seriously, as accounting and audit is our DNA. An article has been written at lenght on this: http://www.pkfavantedge.com/it-audit/pci-dss-so-why-arent-we-qsa/
So – drop us a note at pcidss@pkfmalaysia.com for any queries on ASV scans, PCI-DSS or compliance in general. And no, we don’t know how to solve the resolve the Coronavirus yet, but I hope we get there soon. Stay safe and stay well!
The opinions expressed by our writers and those providing comments are theirs alone, and do not necessarily reflect the views of PKF Avant Edge Sdn Bhd. PKF Avant Edge Sdn Bhd is not responsible for the accuracy of any of the information supplied by our writers.
The material on this site is for general information purposes only and should not be relied upon for making business, legal or other decisions. We make no representations or warranties of any kind, express or implied about the completeness, accuracy, reliability, sustainability or availability with respect to the website or the information, products, services or related graphics contained on the website for any purpose. Any reliance you place on such material is therefore strictly at your own risk.
Certain links on this website will lead to websites not under the control of PKF Avant Edge Sdn Bhd. When you activate these, you will leave our site and we have no control over and accept no liability in respect of materials, products or services available on any website not under our control.
To the extent not prohibited by law, in no circumstances shall PKF Avant Edge Sdn Bhd be liable to you or any third parties for any loss or damage arising directly or indirectly from your use of or inability to use, this site or any of the material contained in it.