While most of our writings are in PCI-DSS and we hardly get a whiff of this phenomena called “Risk Assessment”, it’s a different story when it comes to ISO27001 or what we call ISMS or ISO27k. The 27k is a set of guidelines and standards, to which the ISO27001 is the certifiable standard – but there is plenty of cousins, sisters and brothers involved in the 27k family as well…like 73 of them! They are like rabbits! We are specifically looking, in this article at the venerable ISO27005 standard.
While the term risk assessment carries a little gravitas; especially when faced with stony faced board members after a significant breach – to most organisations, they would go – “Risk assessments? Aren’t those just a bunch of fancy words for ‘guessing what could go wrong’?” Well, yes and no. While risk assessments do involve a bit of crystal ball gazing, they’re a lot more structured and methodical, and there are plenty of methodology to go about it. And when it comes to structure and methodology, one that we constantly fall back on (as we are IT compliance practitioners) is this ISO27005.
Setting the Stage
Before we dive headfirst into the nitty-gritty of ISO27005, let’s set the stage a bit. Imagine you’re about to embark on a road trip from KL to Singapore. Oh wait, we don’t have a reason to go to Singapore since the currency is too strong now. Let’s head up to wonderful Penang. You’ve got your snacks, your playlist, and your destination all set. Luggage, hotel booked, sleeping pills for the kids – all set. But before you hit the road, you check the weather, the condition of your car, and maybe even the traffic situation. You check where is every stop where there is a toilet, since children has bladders the size of thimbles. In essence, as simple as it may sound, is a risk assessment in a nutshell. You’re identifying potential issues (risks) that could derail your trip (objective) and taking steps to mitigate them.
Risk Assessment: The ISO27005 Way
Now, let’s translate that to the business world. ISO27005 is like your road trip checklist, but for information security risks. It’s a standard that provides guidelines for information security risk management, or in simpler terms, it’s a roadmap for identifying, assessing, and managing risks to your information assets.
Step 1: Context Establishment
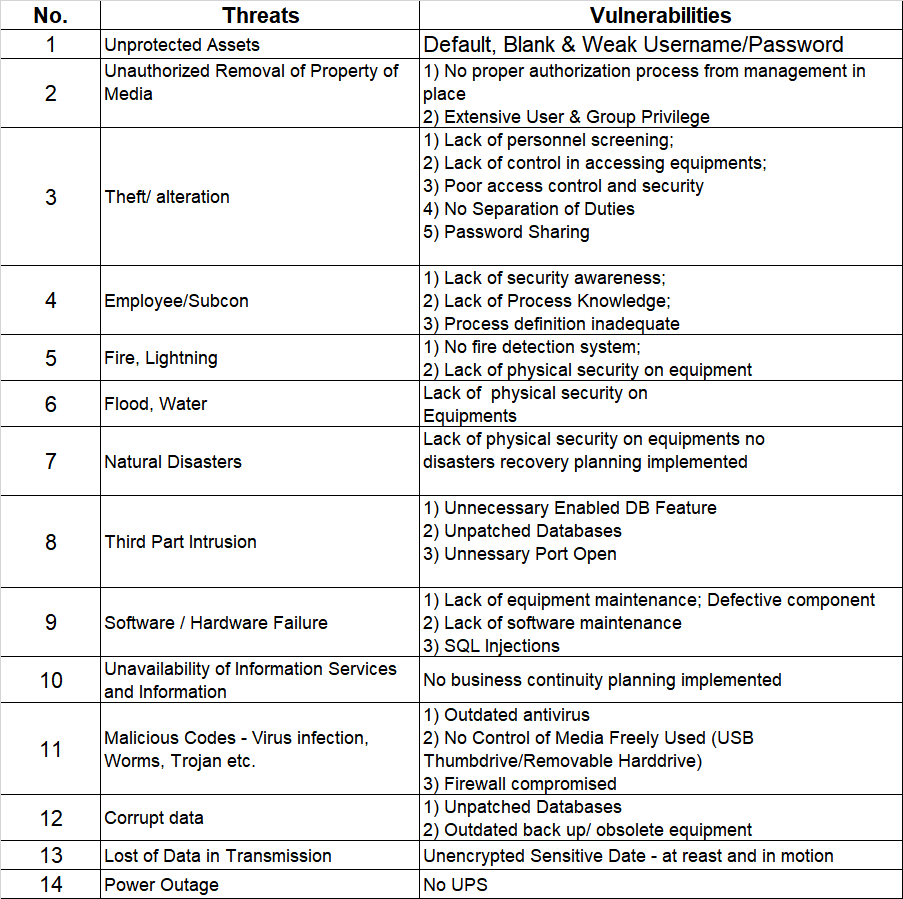
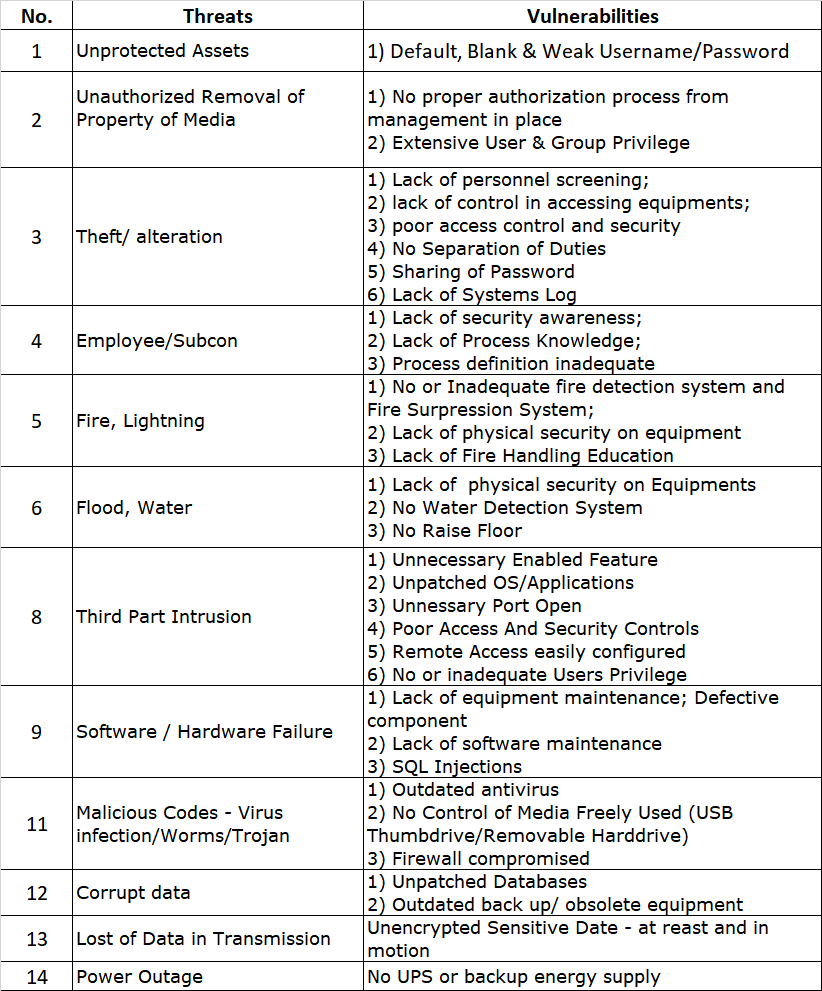
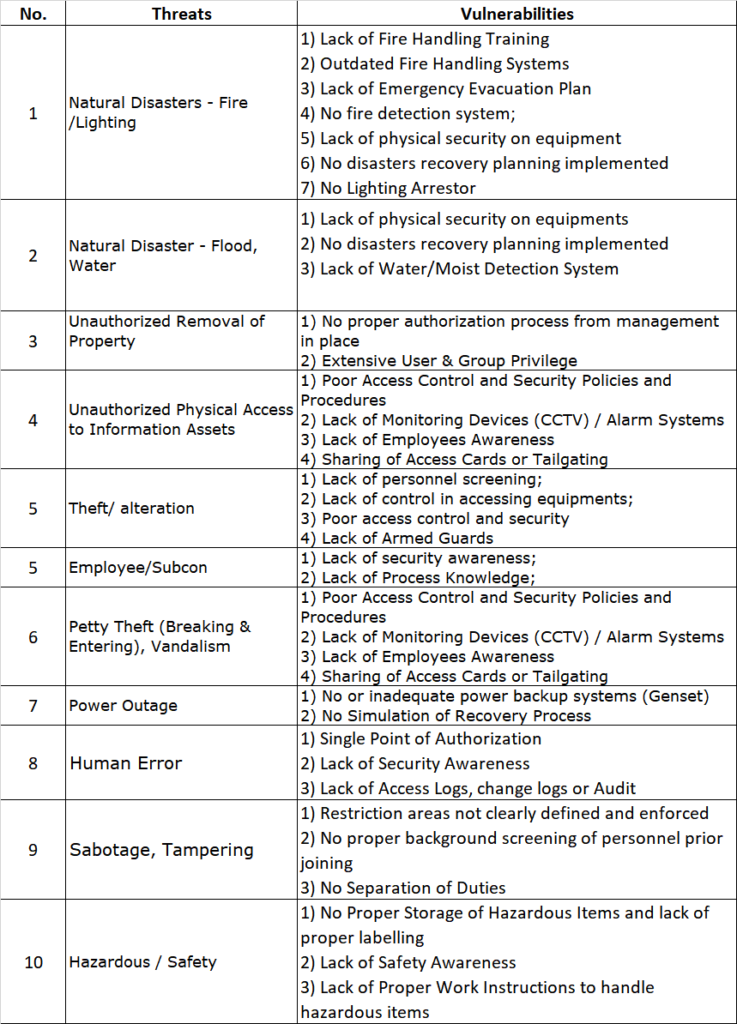
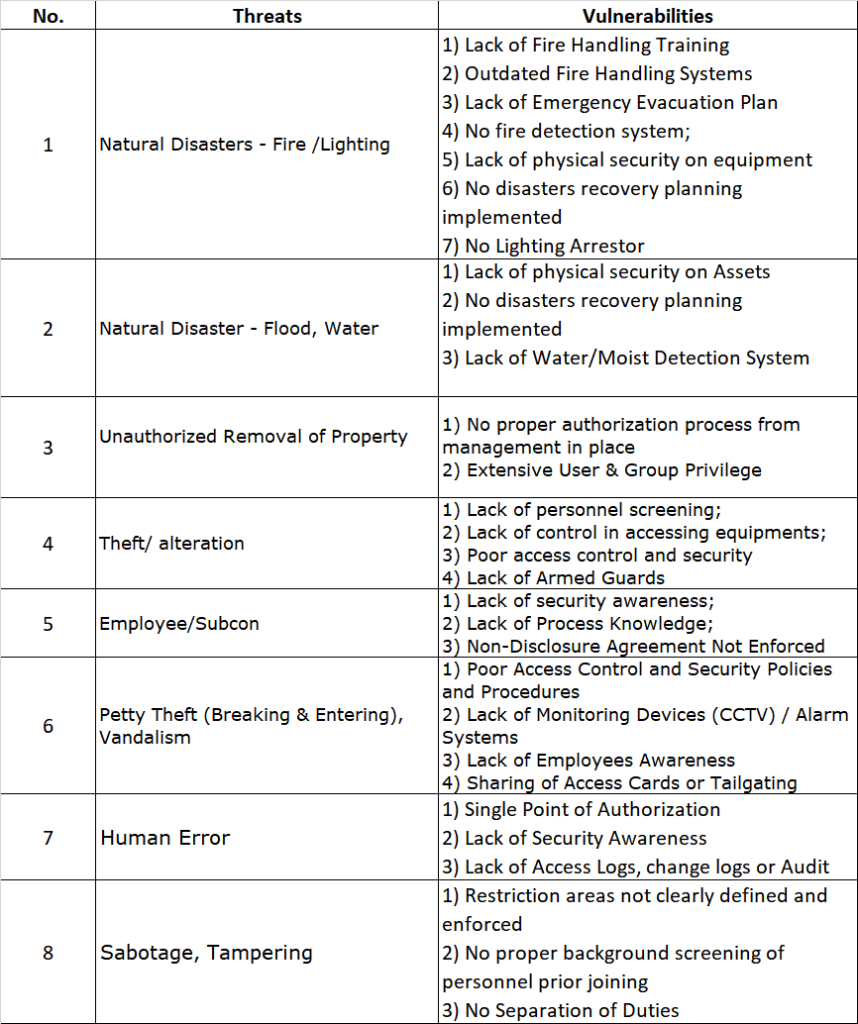
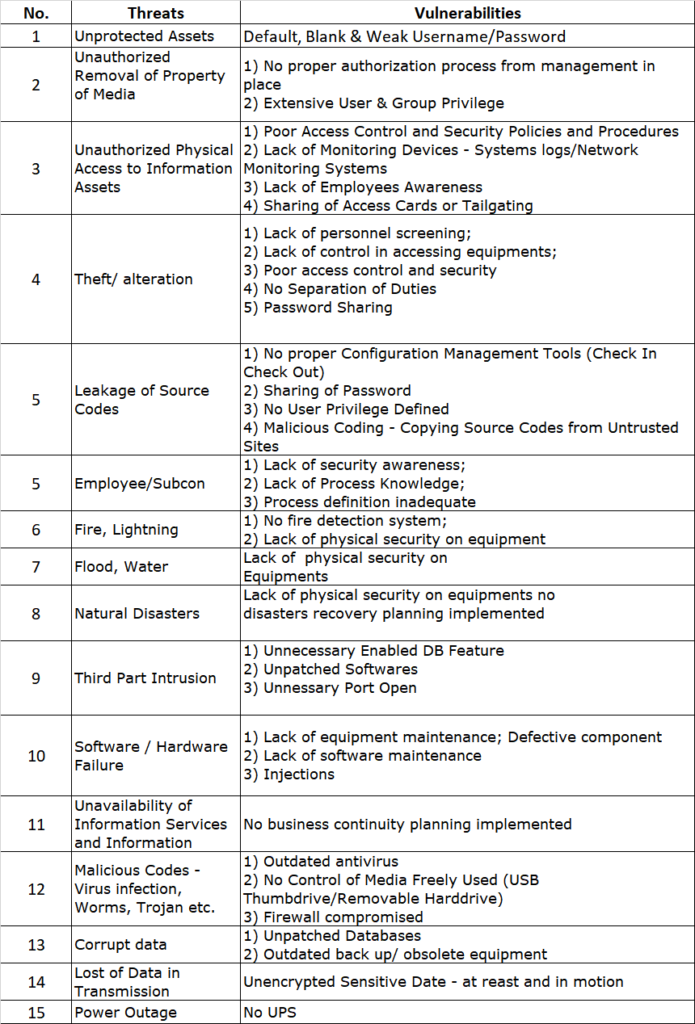
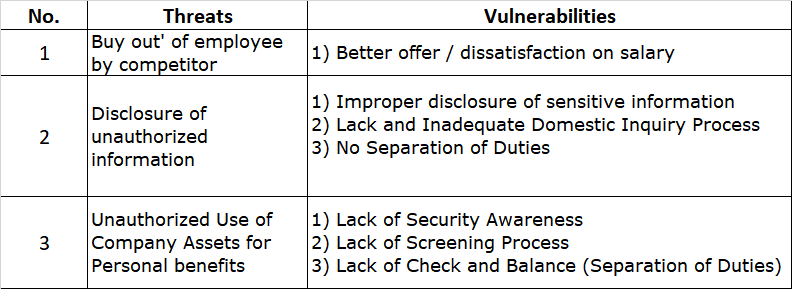
The first step in any risk assessment process is to establish the context. This is like deciding where you’re going on your road trip. In the ISO27005 world, this involves defining the scope and boundaries of your risk assessment. You need to identify what information assets you’re assessing, what the relevant threats and vulnerabilities are, and what the potential impacts could be.
Step 2: Risk Assessment
Once you’ve set the context, it’s time to assess the risks. This is where you identify potential events that could cause harm to your information assets, evaluate the risks associated with these events, and prioritize them based on their potential impact and likelihood.
Let’s say you’re running an online store. One of your information assets could be your customer database. A potential event could be a data breach, the impact could be loss of customer trust and potential legal penalties, and the likelihood could be high if you don’t have strong security measures in place.
Step 3: Risk Treatment
After assessing the risks, the next step is to decide how to treat them. This could involve accepting the risk (if it’s low), avoiding the risk (by not performing the activity that leads to the risk), transferring the risk (to another party), or mitigating the risk (by implementing controls).
In our online store example, you might decide to mitigate the risk of a data breach by implementing stronger security measures, such as encryption and two-factor authentication. Or simply outsource the payment to another PCI-DSS payment gateway thereby transferring part of the risk to them.
Step 4: Risk Acceptance
Once you’ve decided on a treatment, the next step is to accept the risk. This doesn’t mean you’re okay with the risk happening – it just means you’re aware of the risk and have a plan in place to deal with it. The risk after the treatment or controls are what we term as “Residual Risk”. Remember this when faced with stony-faced board members after a significant breach. Say that often.
Step 5: Risk Communication and Consultation
The final step in the ISO27005 process is to communicate and consult with stakeholders about the risk. This could involve informing employees about new security measures, consulting with experts about risk treatment options, or communicating with customers about potential risks.
The ISO27005 Steps
Now, you might be thinking, “That’s all well and good, but where does ISO27005 fit into all this?” Well, think of ISO27005 as the Ten Steps of risk assessments. Except instead of ten, you have a whole lot more. But don’t let that put you off – underneath the jargon, there’s a wealth of wisdom to be found.
Step 1: Identify your Risk!
ISO27005 is big on risk identification. It provides a structured approach to identifying risks, including a comprehensive list of potential threats and vulnerabilities. It’s like a treasure map, but instead of leading to buried gold, it leads to potential risks. Which obviously does not sound as sexy, but you know, risks are….nice, I guess?
Step 2: Analyse your Risk!
Once you’ve identified the risks, ISO27005 guides you through the process of analysing them. This involves evaluating the potential consequences and likelihood of each risk, and assigning a risk level based on these factors. It’s like a crystal ball, helping you see into the future of what could go wrong.
Step 3: Evaluate your Risk!
After analyzing the risks, ISO27005 helps you evaluate them. This involves comparing the risk levels against your risk criteria to determine which risks need to be treated. It’s like a sorting hat, but for risks. This is by far, one of the trickiest to manage and this is where a good risk manager gets paid to do the work. Because in a risk workshop, every stakeholder or process owner will say their risks are highest. Yes, the facilities guy is going to state that the HVAC malfunction will cause the end of the world. Yes, the IT head is going to say that the next breach due to a lack of WAF and SOAR components will bring upon the extermination of the multiverse. And even the guy in charge of the cleaning lady is going to state that if his risk is not looked into, the cleaning lady will likely be an MI6 operative who is sent to assassinate the entire board of directors. So risk manager, do your job!
Step 4: Treat Your Risk!
When it comes to risk treatment, ISO27005 offers a range of options. You can avoid the risk, take on the risk and its potential consequences, share the risk with another party, or implement controls to mitigate the risk. It’s like a choose-your-own-adventure book, but with less adventure and more risk mitigation. It is as bland as it sounds, but hey, do what you gotta do. How many times we have seen risk assessments carried out without any treatment plan? More than we can count. A lot of organisations simply think that identifying risks are good enough, and then accepts every single risk there is. So their risk treatment plan is ACCEPT everything.
Step 5: Monitor and Review Your Risk!
Finally, ISO27005 emphasizes the importance of ongoing risk monitoring and review. This involves keeping an eye on your risks, reviewing your risk assessments, and updating your risk treatments as necessary. It’s like a car’s rear-view mirror, helping you keep an eye on what’s behind you while you focus on the road ahead. A dashboard of risk will help on this, or for the more primitive, a slew of excel sheets can also be used. Whichever way, it needs to be communicated to the risk committee and be able to be updated and reviewed regularly.
Bringing It All Together
So, there you have it – an introduction into the world of ISO27005 risk assessments. It might seem a bit daunting at first, but once you get the hang of it, it’s a powerful tool for managing your information security risks.
Just remember – risk assessments aren’t a one-and-done deal. They’re an ongoing process that needs to be revisited regularly. So, keep your ISO27005 roadmap handy, and don’t be afraid to take a detour or two along the way.
And remember, if you ever feel lost in the wilderness of risk assessments, don’t hesitate to reach out for help. Whether it’s a question about ISO27005, a query about risk treatment options, or ISO in general, drop us a note at avantedge@pkfmalaysia.com and we’ll get back to you.
In the next article, we’ll take a closer look at some of the specific controls recommended by ISO27005, templates that may help you get started, and how they can help you mitigate your information security risks. Until then, happy risk assessing!